
European automotive R&D is in a sprint: electrification programmes, software-defined vehicles, ADAS/AV validation, and factory digital twins all push simulation and AI workloads onto larger GPU/CPU clusters with tighter iteration cycles.
The hidden limiter isn’t compute anymore. It’s the network fabric—moving gradients, sensor datasets, meshes, and MPI messages fast enough that teams aren’t stalled by tail latency, congestion, or unpredictable performance under load.
That’s where Cornelis Networks CN5000 fits: a purpose-built, end-to-end interconnect designed for lossless, congestion-free traffic at 400G with sub-microsecond MPI-latency highlights and fabric-level congestion management, built on the Omni-Path architecture.
And paired with Hammer’s Europe-focused distribution and integration capabilities, it becomes a practical path for automotive organisations to deploy and support high-performance networking across multi-site engineering teams.
Why Automotive Innovation Now Depends on the Network
Automotive engineering workflows are increasingly coupled and iterative:
- Crash & safety simulation (large MPI jobs, lots of small messages, sensitive to latency and tail latency)
- CFD, aero, andthermal analysis (large domain decompositions withall-to-all communication)
- Battery and power electronics modelling (multi-physics, large ensembles)
- ADAS perception and sensor fusion training (distributed AI collective communication)
- Vehicle and plant digital twins (continuous data feeds, rapid scenario testing)
As clusters scale, “good average bandwidth” is no longer sufficient.. Automotive teams need:
- Predictable performance under load
- Low tail latency (so the slowest rank/worker doesn’t dominate step time)
- Congestion management that holds up in real mixed-use conditions—not only best-case traffic patterns
The CN5000 in one minute
CN5000 is positioned as a lossless, congestion-free scale-out network for AI and HPC, designed to keep performance stable as you grow.
At a glance:
- 400G bandwidth per port
- < 1 µs MPI latency (Switch and SuperNIC highlights)
- Architectural building blocks include:
- Credit-based flow control
- Link-level retransmissions
- Fabric-level congestion management
Multipath routingFine-Grained Adaptive Routing (FGAR) and incast-aware flow control called out as part of the congestion-management approach
With more than 240 engineers and technologists dedicated to advancing network innovation, Cornelis and Hammer are focused on unlocking greater data center efficiency. Our complete portfolio of SuperNICs and switches builds on our legacy as the inventors of Omni-Path, an architecture designed to deliver the highest-performance networking in the scale-out era and a foundational feature set for Ultra Ethernet. We bring industry-leading performance, including ultra-low latency, high message rates, and optimized application performance.
Customer impact example:
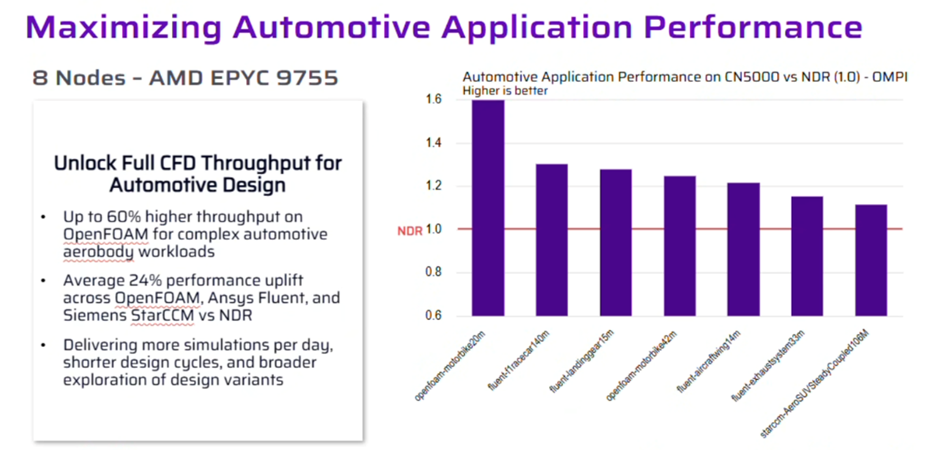
Improved aerodynamic simulation throughput for automotive and mechanical teams, delivering up to a 2× increase in design iteration throughput while reducing reliance on costly physical prototypes and wind tunnel testing.

-
- CN5000 Switch:
- 48 × 400G ports
- CN5000 Switch:
38.4T full duplex bandwidthManagement features including OpenBMC-based management and Redfish support.Implementation Note:
Cornelis describes CN5000 as an end-to-end architecture—meaning the “lossless, congestion-free” design intent is tied to using the CN5000 elements –– switches,SuperNICs, and software––rather than mixing and matching arbitrarily.

CN5000 vs InfiniBand vs RoCEv2 Ethernet (Automotive-Focused Comparison)
|
What you’re comparing |
Cornelis Networks CN5000 (Omni-Path) |
InfiniBand NDR 400 (e.g., Quantum-2) |
400G Ethernet with RoCEv2 |
|
Primary intent |
Purpose-built scale-out fabric for AI + HPC with a lossless, congestion-free design focus. |
HPC/AI fabric with adaptive routing and congestion control as part of the platform value. |
Open-standard Ethernet adapted for low-latency AI/HPC using “lossless” techniques (often PFC + ECN + end-to-end congestion control such as DCQCN). |
|
Link speed class |
400G per port (Switch and SuperNIC options). |
400Gb/s per port (NDR 400). |
Commonly 400G Ethernet; RoCEv2 used for RDMA (design/vendor dependent). |
|
1U switch port density (example) |
48 × 400G Switch; 38.4T full duplex. |
Often 64 × 400Gb/s in 1U (model dependent). |
Varies widely; behaviour depends heavily on ASIC/vendor and your QoS/buffer/ECMP/telemetry and tuning choices. |
|
Congestion / lossless approach (high-level) |
Credit-based flow control, link-level retransmissions, fabric-level congestion management, multipath routing—aimed at predictable performance and reduced tail latency. |
Platform-level congestion control, QoS/virtual lanes, adaptive routing; may include in-network acceleration features (platform specific). |
“Lossless Ethernet” typically uses PFC to avoid drops plus ECN to mark congestion and signal rate reduction; operational success depends on configuration discipline. |
|
Operational watch-outs |
Treat as an end-to-end system (Switch + SuperNIC + software) to align with intended architecture. |
Strong choice where IB ecosystem/tooling and existing workflows are entrenched. |
RoCEv2 outcomes depend heavily on correct PFC/ECN design and ongoing ops discipline; misconfigurations can create severe congestion/latency behaviour. |
What “Lossless, Congestion-Free” Means in Everyday Engineering Outcomes
Faster Solver Turnaround -
In large MPI simulations, job time can be dominated by communication phases (halo exchange, reductions, synchronisation). CN5000 emphasises message-rate and latency optimisation alongside congestion management—aimed at predictable performance under load.
Impact: Shorter wall-clock per design iteration, fewer “mystery slowdowns” at peak utilisation, and better scaling efficiency as nodes are added.
Better distributed AI training efficiency (ADAS/AV and autonomy stacks)
CN5000 positions itself as a fabric designed for AI training and inference that maintains throughput under load by minimising congestion events and tail latency.
Where you’ll feel it: higher GPU utilisation (less time waiting on collectives), more stable step times, improved time-to-train for new sensor domains or model variants.
Practical control through telemetry (not guesswork)
When multiple teams share the same platform, traffic patterns can change hour by hour. CN5000 highlights telemetry and real-time visibility to support workload-aware traffic management.
Where you’ll feel it: quicker root-cause for performance jitter and clearer capacity planning, especially in mixed-use clusters.
Designing CN5000 into real automotive HPC and AI clusters
Treat congestion as the normal case, not an edge case
Automotive platforms are nearly always mixed-use: CAE in the morning, training in the afternoon, digital twin pipelines in the background, and everyone pushing “one more run” before a gate. CN5000 calls out fabric-level congestion management, incast-aware flow control, and adaptive routing to sustain performance under load.
Keep your “lossless” story end-to-end
Cornelis frames “lossless, congestion-free transmission” as an architectural property of CN5000 (Switch + SuperNIC + routing/flow control). In practice: spec it as a system, validate it as a system.
Want to find out more?


