
Smart manufacturing in Europe has moved well beyond PLCs plus dashboards. Today it includes computer vision inspection, AI-driven optimisation, digital twins that require live fidelity, and edge clusters that must behave like mini data centres - reliably, every day.
In that reality, the most common scaling pain often isn’t the model or the GPU. It’s the network: congestion, jitter, and packet loss showing up exactly when you add the next line, the next set of cameras, or the next analytics pipeline.
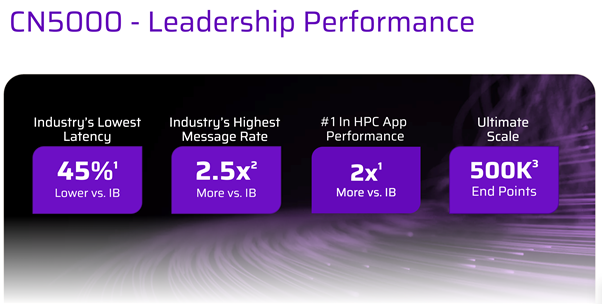
That’s where a very specific capability becomes central: Cornelis CN5000 Omni-Path®, positioned by Cornelis as “the world’s first lossless, congestion-free scale-out network” - paired with Hammer Distribution to make design, supply, and partner-led deployment workable across Europe.[RM1]
Why factory AI stresses networks differently
Industrial data patterns can be a bit… rude. You often see:
- High-rate vision streams feeding inference nodes and storage simultaneously
- Bursty “incast” moments when many devices report together (alarms, batch events, end-of-cycle stats)
- East-west traffic between nodes for analytics, feature extraction, and simulation
- A mix of hard real-time-ish flows (inspection gating, robotic coordination) alongside less critical traffic
In best-effort networks, microbursts and queue pressure can lead to packet drops and retransmissions - one common route to tail-latency spikes. (This is why “lossless Ethernet” designs for RDMA typically lean on mechanisms like PFC and ECN/DCQCN, with careful tuning across the path.)
CN5000’s lossless, congestion-free scale-out fabric

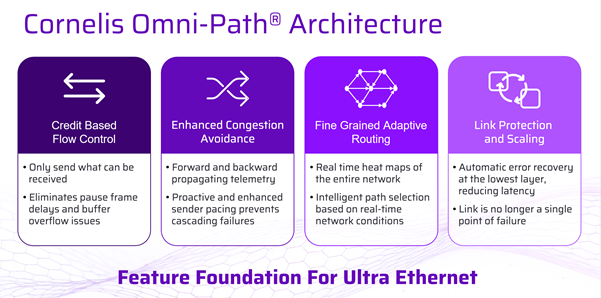
Cornelis describes CN5000 as delivering lossless, congestion-free data transmission using credit-based flow control and dynamic fine-grained adaptive routing, designed to keep throughput and latency predictable as loads rise.
A useful way to frame it for manufacturers:
CN5000 isn’t trying to “cope” with congestion after the fact - it’s designed to prevent loss and manage congestion behaviorally across the fabric.
Cornelis’ CN5000 Director Class Switch materials also call out fine-grained telemetry and real-time traffic analytics to detect congestion and optimise performance, plus high-density scale points such as up to 576 ports of 400G in the director-class platform.
Comparison: CN5000 Omni-Path vs common fabric approaches for factory AI/edge clusters
|
What you care about in smart manufacturing |
Cornelis CN5000 Omni-Path |
RoCEv2 on Ethernet (lossless Ethernet design) |
InfiniBand (typical deployments) |
|
Primary design goal |
Lossless, congestion-free scale-out network for AI/HPC-style traffic patterns |
RDMA over Ethernet, typically engineered to behave losslessly for RDMA classes |
Lossless fabric behaviour with credit-based flow control (common deployments) |
|
How losslessness is approached |
Credit-based flow control + fabric-level congestion behaviour (Cornelis description) |
Often via PFC + ECN/DCQCN (end-to-end configuration and tuning required) |
Credit-based link flow control to avoid drops in-fabric (typical characteristic) |
|
Congestion management |
Adaptive routing + congestion-aware fabric behaviour (Cornelis description) |
ECN/DCQCN-style congestion signalling and rate adjustment; PFC as safety net |
Built-in fabric mechanisms and mature operational tooling in many HPC environments |
|
Operational emphasis |
Scale-out efficiency + telemetry/traffic analytics (Cornelis) |
Strongly dependent on consistent PFC/ECN configuration across the path |
Often chosen where deterministic fabric behaviour is prioritised |
|
Why it matters on the factory edge |
Helps keep latency predictable when vision + analytics + simulation collide in the same pod |
Can work well, but “lossless Ethernet” engineering becomes part of the project scope |
A known option for low-latency, lossless fabrics (more typical in HPC environments) |
The point isn’t “there’s only one right answer.” It’s that smart manufacturing edge clusters behave like scaled-down AI/HPC environments, and CN5000 is explicitly positioned for those traffic patterns - lossless, congestion-managed, and observable at scale.
Where Hammer fits turning a fabric into a deployable European solution
Manufacturers rarely buy “a fabric” in isolation. They buy a partner-delivered outcome: a validated design, integrated rack builds, logistics that match rollout windows, and supportability that won’t collapse during the first incident.
Hammer positions itself around exactly that kind of enablement, including in-house rack-scale configuration, testing and logistics, plus a consultative design approach.
Industry coverage also describes Hammer’s evolution into a broader European footprint with added offices and facilities supporting ready-made datacentre solutions.
So, in a Cornelis context, Hammer’s role is the pragmatic one: helping the channel deliver CN5000 in a way that matches how European manufacturing tends to roll projects out - pilot pod → first line → first site → multi-site repeatability.
Use cases that map neatly to CN5000’s feature set
1) Vision inspection pods that can’t tolerate performance wobble
High-resolution inspection creates sustained throughput plus bursts (metadata, storage writes, event triggers). Lossless, congestion-managed behaviour helps reduce the “it was fine until we added two more cameras” effect.
2) Digital twin loops that need live fidelity
A twin fed late becomes a reporting tool, not an operational tool. CN5000’s positioning around congestion-free transmission plus telemetry/analytics is directly relevant when you need stable, observable flows at the edge.
3) Factory analytics at scale - without the brittle networking phase
As you scale from one line to many, burst pressure and incast-style behaviour become more common. If packet loss starts driving retransmissions and tail latency, stability suffers. A fabric designed to stay lossless under load changes the scaling story.
Reference architecture: a “factory AI pod” that scales
A simple, repeatable pattern that tends to work well is the factory AI pod: a self-contained edge cluster that runs the real-time bits locally, while still integrating upstream for training and fleet-wide optimisation.
Core components
- 4–32 GPU/CPU nodes for inference + analytics
- Local high-performance storage (vision buffers, features, short retention)
- A dedicated scale-out fabric for east-west traffic (where most of the pain lives)
- Secure north-south connectivity to the plant network and central services
Where CN5000 sits:
- As the east-west fabric between compute and storage to keep latency predictable under mixed load
- Providing telemetry and traffic analytics to spot congestion and optimise performance before operators notice drift
Where Hammer helps:
- Partner-led validated designs and rack integration so each pod deployment is repeatable across sites
The big win: this architecture scales operationally. Once you can deploy Pod v1 cleanly, you can replicate it across plants with far fewer unknowns.
Operationalising performance with telemetry (because factories don’t have time for guesswork)
Networking problems in manufacturing rarely arrive politely. They arrive as:
- intermittent inspection misses
- unexplained inference delays
- a line that “feels slower” after an update
- overnight analytics jobs that suddenly overrun the maintenance window
This is why CN5000’s emphasis on fine-grained telemetry and real-time traffic analytics is more than a nice feature - it’s an operations enabler. Cornelis explicitly describes telemetry/analytics used to detect congestion and optimise performance across large endpoint counts.
In practical terms, telemetry supports:
- Faster root-cause isolation (compute, storage, or fabric?)
- Proactive tuning (spot hot links and patterns early)
- Safer scaling (add cameras/nodes with evidence, not hope)
And because Hammer supports partner delivery and integration, you can bake those operational expectations into the deployment from day one rather than retrofitting observability after the first production scare.
Closing: treat the network as first-class architecture
If you’re serious about accelerating smart manufacturing across Europe, treat the network as a first-class part of the architecture.
Cornelis CN5000 brings a fabric designed and marketed for lossless, congestion-free scale-out performance, with adaptive routing and deep visibility.
Hammer helps make that capability deployable through the European channel - repeatable, supportable, and built for growth.
FAQ: Cornelis CN5000 in smart manufacturing
What is Cornelis CN5000 used for in smart manufacturing?
CN5000 is used as the east–west interconnect inside a factory “AI pod”; the high-speed fabric between compute nodes (GPU/CPU), local storage, and analytics services. In smart manufacturing, that internal traffic is where vision streams, feature extraction, and simulation/analytics collide, and where congestion shows up first as you scale cameras, lines, and pipelines. The goal is predictable latency and throughput under load, not just high peak bandwidth.
Why do factory AI workloads cause network congestion and jitter?
Factory data tends to be high-rate, bursty, and synchronized:
- Multiple vision feeds can hit inference and storage at the same time.
- “Incast” moments happen when many devices report together (alarms, end-of-cycle events, batch completions).
- You get sustained throughput plus microbursts, which increases queue pressure.
On best-effort networks, that often turns into queue buildup, packet drops, and retransmissions, which is exactly how tail latency spikes appear, usually right when you add “just one more” camera, line, or pipeline.
How does CN5000 differ from “lossless Ethernet” designs like RoCEv2?
In many RoCEv2 environments, “lossless Ethernet” behaviour is achieved by engineering the Ethernet path (commonly with PFC + ECN/DCQCN) and tuning it end-to-end.
CN5000 is typically positioned as taking a different approach: credit-based flow control and fabric-level congestion handling (plus adaptive routing) to keep loss and congestion from snowballing.
The practical difference is where the operational complexity lives:
- RoCEv2: more in Ethernet configuration/tuning discipline
- CN5000: more in fabric design + policy, with less reliance on “lossless Ethernet” knobs
When would a manufacturer choose CN5000 Omni-Path vs InfiniBand?
Both target predictable, low-jitter behaviour for scale-out compute. The decision usually comes down to ecosystem and operations:
- Choose the option that best fits your existing toolchain, skills, support model, and procurement reality.
- Use a “pod” lens: if your edge cluster behaves like a mini AI/HPC environment and you care most about stable scaling under mixed workloads, compare them on real collective-heavy and bursty factory patterns, not just clean lab benchmarks.
How do telemetry and traffic analytics help operations on the factory edge?
Factory networking issues rarely present as tidy alarms. They show up as:
- intermittent inspection misses
- unexplained inference delays
- analytics jobs that overrun maintenance windows
Fine-grained telemetry helps you answer “compute, storage, or fabric?” quickly, and spot hot links, congestion patterns, or noisy-neighbour effects before operators feel performance drift. That’s what makes scaling safer; you add cameras/nodes with evidence, not guesswork.
What role does Hammer Distribution play in deploying CN5000 across Europe?
Hammer’s role is usually to make the fabric deployable and repeatable rather than “just bought”:
- validated designs mapped to the workload
- integrated rack builds and pre-testing
- logistics aligned to rollout windows
- support patterns for real incidents (day-2 operations)
In practice, this supports the common manufacturer path: pilot pod → first line → first site → multi-site repeatability.
What is a “factory AI pod” and where does the network fit?
A factory AI pod is a repeatable edge cluster that runs real-time inference and analytics locally, while integrating upstream for training and fleet optimization. A typical pattern includes:
- ~4–32 GPU/CPU nodes
- local high-performance storage
- a dedicated east–west fabric
Most scaling pain lives in that east–west layer, so the fabric is the piece you choose to keep latency stable under mixed, bursty loads.
Which smart manufacturing use cases benefit most from a lossless, congestion-managed fabric?
Use cases that mix sustained throughput with bursts and synchronization:
- Vision inspection pods (streams + metadata bursts + storage writes)
- Digital twin loops where lateness turns “operations” into “reporting”
- Scaled analytics across many lines (frequent incast and shuffle-like patterns)
The common theme: avoiding retransmission-driven tail latency that destabilizes real-time performance.
What are the common signs the network is the bottleneck in edge AI?
Symptoms that feel “mysterious” in production:
- Intermittent inspection misses or inconsistent reject rates
- Uneven inference timing (same model, different latency moments)
- The line “feels slower” after scaling or updates
- Overnight/maintenance-window jobs suddenly exceed the window
If the system was stable and then degrades after adding the next camera/line/pipeline, the fabric is a frequent suspect, especially when the problem appears only under peak concurrency.
Want to find out more?


