
European universities are in a bit of a “now or never” moment for compute. Research groups want bigger GPU partitions for model training, more predictable MPI performance for simulation, and tighter turnaround times for shared, multi-tenant clusters. At the same time, budgets are scrutinised, energy targets are getting sharper, and sovereignty expectations are rising.
In practice, a lot of university AI and HPC upgrades don’t fail because of the CPUs/GPUs. They stall because the interconnect can’t sustain high throughput under load without unpredictable latency spikes. That’s exactly the problem space Cornelis CN5000 is built for, and why pairing Cornelis technology with Hammer’s European distribution and delivery model is a pragmatic path for universities that need performance and operational sanity.
What changes when a university cluster becomes “AI + HPC” at scale?
University environments are uniquely demanding because they combine:
• Tightly-coupled HPC (MPI collectives, latency sensitivity, long-running jobs)
• Distributed AI training (bandwidth-hungry, communication-heavy patterns like all-reduce)
• Multi-tenancy (lots of users, lots of job shapes, unpredictable concurrency)
• Shared infrastructure constraints (limited rack space, power caps, procurement cycles)
In that mix, the interconnect becomes the “silent limiter”. Congestion events and long-tail latency don’t just slow a single run. They skew fairness, waste allocation hours, and make performance hard to trust.
Cornelis CN5000 in plain terms: why it’s different
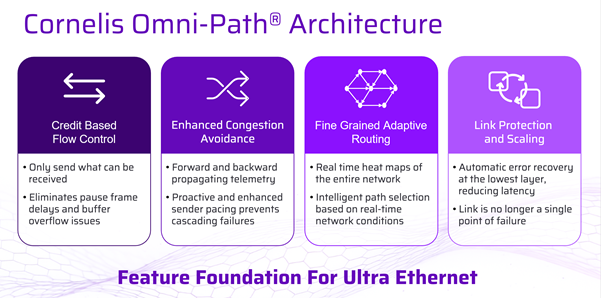
Cornelis CN5000 is an end-to-end HPC/AI interconnect family (switching, host interfaces, cabling, and software) designed around a simple goal: keep throughput high and latency stable when the fabric is busy, which is the exact condition most university clusters live in.

Key ideas you’ll see associated with CN5000 deployments:
• High bandwidth per port to support scale-out GPU and CPU clusters
• Lossless / congestion-avoiding behaviour aimed at smoothing performance under load
• Adaptive routing and deep telemetry to steer around hotspots and diagnose issues quickly
• Scalable topologies from smaller pods through to large multi-rack fabrics

Comparison table: CN5000 vs common university interconnect options
The table below stays deliberately practical: it’s about operational reality in university AI/HPC, not just theoretical peak figures.
|
What universities care about |
Cornelis CN5000 Omni-Path product family |
Ethernet (incl. RoCE variants) |
InfiniBand |
|
Predictable performance under heavy load |
Designed to sustain throughput with congestion-aware behaviour |
Can be strong, but often needs careful tuning (PFC/ECN/QoS) to avoid loss/latency spikes |
Typically strong for HPC/AI, but depends on fabric design and operations maturity |
|
Latency sensitivity (MPI collectives, tightly coupled jobs) |
Built for low-latency scale-out with HPC in mind |
Usually higher/lumpier latency unless engineered aggressively |
Generally excellent latency characteristics for HPC patterns |
|
Multi-tenant fairness (mixed job sizes, lots of users) |
Focus on reducing congestion-driven variability |
Can be challenging without disciplined QoS and ongoing policy management |
Strong, though partitioning and policy still matter at scale |
|
Operational complexity |
Purpose-built tooling/telemetry for the fabric |
Familiar skill base, but “lossless Ethernet” can get complicated fast |
Specialist skill set; mature tooling, but can be more niche |
|
Cost predictability (end-to-end fabric) |
Single-vendor fabric stack can simplify BOM and support |
Wide vendor choice; costs vary heavily by design (optics, switches, tuning effort) |
Often premium; ecosystem is mature but can be costlier per port |
|
Best fit in universities |
AI + HPC where performance consistency matters and congestion is the enemy |
Mixed enterprise + research environments that value standardisation and existing Ethernet skills |
HPC-heavy sites and national centres where IB is already the norm |
How to use this table: if your cluster is mostly small, embarrassingly parallel workloads, the fabric matters less. But if you’re doing distributed training, MPI-heavy simulation, or you’re fighting “good days and bad days” performance, interconnect choice becomes a first-order design decision.
Where CN5000 helps most in university AI and HPC clusters
Faster training isn’t just “more GPUs”, it’s keeping GPUs fed
Distributed training can become communication-bound as you scale out. When the network behaves inconsistently under load, you see utilisation dips, synchronisation stalls, and jittery step times. A fabric designed to stay stable under concurrency helps training runs finish sooner and with fewer odd “why was that run slower?” mysteries.
Predictable HPC runs in a multi-tenant scheduler
Universities care about tail latency because one slow rank can drag an entire MPI job. A congestion-resilient fabric reduces those long-tail behaviours and makes performance more repeatable across busy periods (the real test, honestly).
Scaling without “cabling chaos”
As clusters grow, topology and cabling strategy can make or break operations. Planning for expansion, port density, tiering, and sensible pathways to add racks helps you avoid a mid-life refactor that no one has time for.
Why “Cornelis and Hammer” is a useful pairing in Europe
For European universities, the challenge isn’t only choosing the right fabric. It’s sourcing, integrating, staging, and supporting it across procurement frameworks, partner ecosystems, and strict change windows.
Hammer’s role in the channel is valuable because it can help universities and integrators with:
• Practical availability and sourcing across EMEA procurement routes
• Design-to-delivery coordination (getting the right mix of switching, host connectivity, and cabling on day one)
• Lifecycle pragmatism (spares strategy, phased expansions, and keeping the fabric consistent over time)
In short: Cornelis brings the purpose-built interconnect; Hammer helps make it land cleanly in European university reality.
Migration strategy for universities moving off legacy fabrics
Most universities aren’t building “greenfield” clusters. You’re usually migrating from something like older Ethernet, legacy IB generations, or a mixed bag that grew organically.
A low-drama migration approach typically looks like this:
- Start with a dedicated CN5000 pod
Build a contained partition (often GPU-first) with its own leaf/spine (or equivalent) design. This lets you validate performance without disrupting the existing estate. - Use the scheduler to manage user experience
Create clear partitions/queues so research groups can opt into the new fabric, then standardise job templates and comms libraries for repeatability. - Expand by workload gravity, not politics
Move the most communication-heavy workloads first: distributed training, MPI-heavy simulation, large-scale analytics. These show measurable wins quickly. - Plan the storage path explicitly
Don’t let storage networking become an afterthought. Decide early whether storage traffic is separate or converged, and design for predictable contention behaviour. - Operationalise telemetry and runbooks
The best interconnect in the world still needs day-2 discipline: baseline metrics, congestion alarms, and a clear escalation path when performance changes.
This staged method tends to keep researchers productive while the platform evolves underneath them.
European procurement, sustainability, and sovereignty considerations
European universities often have to balance performance with constraints that don’t show up on a spec sheet:
• Energy efficiency targets and carbon reporting
If you’re tracking energy per job or per research output, performance consistency matters because wasted time is wasted power. A smoother fabric can reduce “compute churn” caused by stalls and retries.
• Sovereignty and data locality
Many projects now care where training happens, where datasets sit, and who can support the infrastructure. Choosing a solution with strong European channel coverage and support pathways can simplify governance.
• Frameworks, grants, and phased funding
Cluster upgrades are commonly tied to grant milestones. Designing an interconnect that scales cleanly, without a full redesign every time funding lands, keeps the roadmap realistic.
This is where the Cornelis + Hammer combination is practical: it supports a European delivery model while keeping the technical core focused on AI/HPC outcomes.
Reference architecture patterns for European universities using CN5000
Pattern A: “AI partition + classic HPC partition” on a shared fabric
• AI partition: GPU nodes (training + fine-tuning), heavy collective comms
• HPC partition: CPU and accelerator nodes for simulation/analytics
• Goal: isolate noisy neighbours at the scheduler/QoS level while benefitting from a scalable fabric
Pattern B: Departmental pods that later unify
Start with smaller pods, then expand as grants arrive. Keep the topology consistent, document cabling standards, and avoid “one-off” exceptions that become permanent problems.
Pattern C: Dense core for shared services and collaborations
If your university is part of regional or national collaborations, a higher-density core approach can reduce tiers and simplify operations as the estate grows.
FAQ: CN5000 on busy university clusters (polished + tightened)
How does Cornelis CN5000 improve performance consistency on busy university clusters?
CN5000 is positioned as an end-to-end interconnect designed to keep throughput high and latency stable when the fabric is busy, which is exactly when multi-tenant university clusters struggle. In practice, that matters because congestion and long-tail latency can make “good days and bad days” performance. A congestion-aware fabric helps reduce jitter, improves repeatability, and makes fair scheduling outcomes easier to trust.
When does the interconnect become the bottleneck for AI training and HPC?
It usually becomes a first-order constraint once you scale beyond small, embarrassingly parallel workloads. Distributed training can become communication-bound as you add more GPUs, and tightly-coupled MPI jobs can be dragged down by one slow rank. In multi-tenant environments, unpredictable concurrency can trigger congestion events that waste allocation hours and skew fairness across users.
Is Cornelis CN5000 Ethernet or InfiniBand, and does that distinction matter?
The article frames CN5000 in the Omni-Path family rather than positioning it as Ethernet or InfiniBand. For most university teams, the more useful question is whether the fabric delivers predictable performance under real multi-tenant load. If your pain is variability under congestion, the “label” matters less than how stable latency and throughput remain when the cluster is busy.
What are the main differences between CN5000, Ethernet/RoCE, and InfiniBand for universities?
The practical trade-offs described are about operational reality. CN5000 is presented as designed for predictable performance under heavy load with congestion-aware behaviour and purpose-built telemetry. Ethernet can be familiar, but “lossless Ethernet” often needs careful tuning to avoid loss and latency spikes. InfiniBand is typically strong for HPC/AI, but fabric design choices and specialist operations maturity still matter at scale.
How can CN5000 help with distributed AI training efficiency beyond “adding more GPUs”?
The article’s core point is that faster training often comes from keeping GPUs fed consistently, not just increasing GPU count. When networks behave inconsistently under load, you can see synchronisation stalls, utilisation dips, and jittery step times. A fabric designed to stay stable under concurrency reduces those stalls so training finishes sooner and performance is less mysterious run-to-run.
What’s a low-drama migration plan for moving off legacy Ethernet or older interconnects?
A staged approach is outlined. Start with a dedicated CN5000 pod, often GPU-first, to validate performance without disrupting the existing estate. Use the scheduler to create clear partitions and queues so teams can opt in and standardise job templates and comms libraries. Then expand by workload gravity: move communication-heavy distributed training and MPI-heavy simulation first, while operationalising telemetry and runbooks.
How should universities think about topology and cabling as clusters scale?
The article argues scaling problems often show up as “cabling chaos” and mid-life refactors. Planning for expansion, including port density, tiering, and how new racks join the fabric, helps keep operations sane. Reference patterns include starting with smaller departmental pods that later unify, keeping topology consistent, and documenting cabling standards to avoid one-off exceptions that become permanent pain points.
Why does storage networking need to be planned alongside the interconnect?
Storage is called out as something that shouldn’t be an afterthought during migration or expansion. You need an explicit decision on whether storage traffic is separate or converged, and a design that avoids unpredictable contention. Without that, you can end up with “mystery slowdowns” that look like compute issues but are really storage path contention under shared load.
How do sustainability and sovereignty requirements influence interconnect choices in Europe?
The article highlights that European universities often have energy targets, carbon reporting, and governance expectations around data locality and support pathways. Performance consistency matters because wasted time is wasted power, especially when stalls and retries create compute churn. A scalable design that grows cleanly with phased funding and a European delivery model can also simplify procurement frameworks and long-term governance.
Want to find out more?


